Submission 2025-05-01¶
Execution Throughput and Latency¶
This section microbenchmarks the execution throughput and latency of FP32 Neon instructions.
1. Microbenchmark the execution throughput of the following instructions:¶
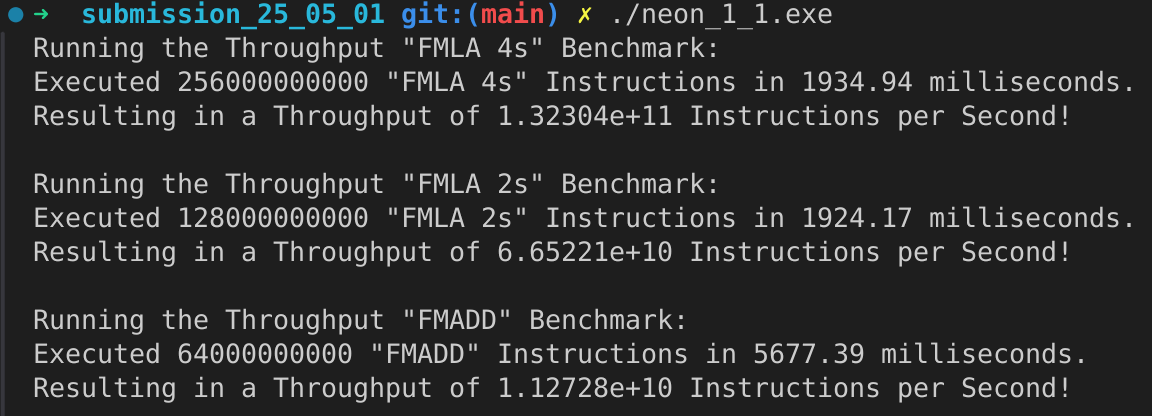
FMLA (vector) with arrangement specifier 4S
File:
submissions/submission_25_05_01/neon_1_1.sDriver:
submissions/submission_25_05_01/neon_1_1_driver.cppCompilation:
g++ -o neon_1_1.exe neon_1_1_driver.cpp neon_1_1.sWe have \(13.2304 \cdot 10^{10}\) instructions per second. That are \(13.2304 \cdot 10^{10} / 8 = 16.538 \cdot 10^9\) instructions per ALU per second. This aligns with a throughput of \(\approx 4\) instruction per cycle, as it is known from benchmarks that the performance cores of the M4 chip have a clock speed of 4.4 GHz.
FMLA (vector) with arrangement specifier 2S
File:
submissions/submission_25_05_01/neon_1_1.sDriver:
submissions/submission_25_05_01/neon_1_1_driver.cppCompilation:
g++ -o neon_1_1.exe neon_1_1_driver.cpp neon_1_1.sWe have \(6.65221 \cdot 10^{10}\) instructions per second. That are \(6.65221 \cdot 10^{10} / 8 = 8.31526 \cdot 10^9\) instructions per ALU per second. This aligns with a throughput of \(\approx 2\) instruction per cycle, as it is known from benchmarks that the performance cores of the M4 chip have a clock speed of 4.4 GHz.
FMADD (scalar), single-precision variant
File:
submissions/submission_25_05_01/neon_1_1.sDriver:
submissions/submission_25_05_01/neon_1_1_driver.cppCompilation:
g++ -o neon_1_1.exe neon_1_1_driver.cpp neon_1_1.sWe have \(1.12728 \cdot 10^{10}\) instructions per second. That are \(1.12728 \cdot 10^{10} / 8 = 1.4091 \cdot 10^9\) instructions per ALU per second. This aligns with a throughput of \(\approx 1/3\) instruction per cycle, as it is known from benchmarks that the performance cores of the M4 chip have a clock speed of 4.4 GHz.
2. Microbenchmark the execution latency of FMLA (vector) with arrangement specifier 4S. Consider the following two cases:¶

Dependency on one of the source registers
File:
submissions/submission_25_05_01/neon_1_2.sDriver:
submissions/submission_25_05_01/neon_1_2_driver.cppCompilation:
g++ -o neon_1_2.exe neon_1_2_driver.cpp neon_1_2.sWe have \(11.4961 \cdot 10^9\) instruction per seconds in a single ALU. Resulting in a latency of \(\approx 1/3\) cycle for the known clock speed of 4.4 GHz.
Dependency on the destination register only
File:
submissions/submission_25_05_01/neon_1_2.sDriver:
submissions/submission_25_05_01/neon_1_2_driver.cppCompilation:
g++ -o neon_1_2.exe neon_1_2_driver.cpp neon_1_2.sWe have \(11.7019 \cdot 10^9\) instruction per seconds in a single ALU. Resulting in a latency of \(\approx 1/3\) cycle for the known clock speed of 4.4 GHz.
Microkernel¶
1. Implement a Neon microkernel that computes C+=AB for M=16, N=6, and K=1.¶
Files
submissions/submission_25_05_01/neon_2_simple.sDriver
submissions/submission_25_05_01/neon_2_driver.cpp
Implementation loops over each column over the matrix c to be calculated.
1 ...
2 // Offset the used leading dimension by the size of floats (4byte == 2 lshifts)
3 lsl x3, x3, #2 // x3 * 4 = x3 * sizeof(float)
4 lsl x4, x4, #2 // x4 * 4 = x4 * sizeof(float)
5 lsl x5, x5, #2 // x5 * 4 = x5 * sizeof(float)
6
7 // Load all data from the 16x1 matrix a
8 ld1 {v0.4s, v1.4s, v2.4s, v3.4s}, [x0]
9
10 // Init the loop counter
11 mov x6, #6
12process_next_column:
13 // Iteration -= 1
14 subs x6, x6, #1
15
16 // Load next element from the 1x6 matrix
17 // ldr s4, [x1], #4 // one-liner but not using the argument offset
18 ldr s4, [x1]
19 add x1, x1, x4
20
21 // Load next column from the 16x6 matrix c
22 ld1 {v17.4s, v18.4s, v19.4s, v20.4s}, [x2]
23
24 // Calculate the next row of c
25 fmla v17.4s, v0.4s, v4.s[0]
26 fmla v18.4s, v1.4s, v4.s[0]
27 fmla v19.4s, v2.4s, v4.s[0]
28 fmla v20.4s, v3.4s, v4.s[0]
29
30 // Store the result back to memory
31 st1 {v17.4s, v18.4s, v19.4s, v20.4s}, [x2], x5
32
33 // Compare and branch on not-zero
34 cbnz x6, process_next_column
35 ...
2. Test and optimize your microkernel. Report its performance in GFLOPS.¶
- Files
submissions/submission_25_05_01/neon_2.hsubmissions/submission_25_05_01/neon_2_unrolled.s
Tests
submissions/submission_25_05_01/neon_2.test.cppBenchmarks
submissions/submission_25_05_01/neon_2.bench.cpp
Optimization
To optimize the kernel we unrolled the loop into 3 different register ranges (v15-v28, v17-v20, v21-v24),
to allow for less dependency between the calculation of columns.
These 3 different fmla blocks gets repeated with .rept 2 to achieve the total of 6 column of calculation.
1...
2.rept 2
3// Load first element from the 1x6 matrix b
4ldr s4, [x1]
5add x1, x1, x4
6// Load first column from the 16x6 matrix c
7ld1 {v25.4s, v26.4s, v27.4s, v28.4s}, [x2]
8
9// Calculate first column of c
10fmla v25.4s, v0.4s, v4.s[0]
11fmla v26.4s, v1.4s, v4.s[0]
12fmla v27.4s, v2.4s, v4.s[0]
13fmla v28.4s, v3.4s, v4.s[0]
14
15// Store first column back to memory
16st1 {v25.4s, v26.4s, v27.4s, v28.4s}, [x2], x5
17
18// Load second element from the 1x6 matrix b
19ldr s4, [x1]
20add x1, x1, x4
21// Load second column from the 16x6 matrix c
22ld1 {v17.4s, v18.4s, v19.4s, v20.4s}, [x2]
23
24// Calculate second column of c
25fmla v17.4s, v0.4s, v4.s[0]
26fmla v18.4s, v1.4s, v4.s[0]
27fmla v19.4s, v2.4s, v4.s[0]
28fmla v20.4s, v3.4s, v4.s[0]
29
30// Store second column back to memory
31st1 {v17.4s, v18.4s, v19.4s, v20.4s}, [x2], x5
32
33// Load third element from the 1x6 matrix b
34ldr s4, [x1]
35add x1, x1, x4
36// Load third column from the 16x6 matrix c
37ld1 {v21.4s, v22.4s, v23.4s, v24.4s}, [x2]
38
39// Calculated third column of c
40fmla v21.4s, v0.4s, v4.s[0]
41fmla v22.4s, v1.4s, v4.s[0]
42fmla v23.4s, v2.4s, v4.s[0]
43fmla v24.4s, v3.4s, v4.s[0]
44
45// Store third column back to memory
46st1 {v21.4s, v22.4s, v23.4s, v24.4s}, [x2], x5
47.endr
48...
Benchmarks
We run the benchmark with the following command:
./benchmarks --benchmark_counters_tabular=true --benchmark_repetitions=10 --benchmark_report_aggregates_only=true
Therefore we do 10 repetitions of the benchmark which do about 120 000 000 iterations each on our matmul kernels.
----------------------------------------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations FLOPS
----------------------------------------------------------------------------------------------------------------------------------
Gemm16x6x1Fixture/BM_matmul_16_6_1_simple/min_warmup_time:1.000_mean 5.84 ns 5.82 ns 10 33.0036G/s
Gemm16x6x1Fixture/BM_matmul_16_6_1_simple/min_warmup_time:1.000_median 5.83 ns 5.81 ns 10 33.0317G/s
Gemm16x6x1Fixture/BM_matmul_16_6_1_simple/min_warmup_time:1.000_stddev 0.025 ns 0.025 ns 10 143.339M/s
Gemm16x6x1Fixture/BM_matmul_16_6_1_simple/min_warmup_time:1.000_cv 0.43 % 0.44 % 10 0.43%
Gemm16x6x1Fixture/BM_matmul_16_6_1_unrolled/min_warmup_time:1.000_mean 5.71 ns 5.69 ns 10 33.7234G/s
Gemm16x6x1Fixture/BM_matmul_16_6_1_unrolled/min_warmup_time:1.000_median 5.70 ns 5.68 ns 10 33.7732G/s
Gemm16x6x1Fixture/BM_matmul_16_6_1_unrolled/min_warmup_time:1.000_stddev 0.038 ns 0.038 ns 10 224.892M/s
Gemm16x6x1Fixture/BM_matmul_16_6_1_unrolled/min_warmup_time:1.000_cv 0.67 % 0.67 % 10 0.67
We see that the simple first implementation of our matmul kernel gets about 33.0 GFLOPS. The optimized unrolled version gets about 0.7 GFLOPS more resulting in 33.7 GFLOPS.
Loops¶
1. Loop over K: Implement a kernel that computes C+=AB for M=16, N=6 and K=64.¶
File
submissions/submission_25_05_01/neon_3_1.s
1 ...
2 // Offset the used leading dimension by the size of floats
3 lsl x3, x3, #2 // x3 * 4 = x3 * sizeof(float)
4 lsl x4, x4, #2 // x4 * 4 = x4 * sizeof(float)
5 lsl x5, x5, #2 // x5 * 4 = x5 * sizeof(float)
6
7 mov x6, x1 // Store the initial value of x1, to be restored in the next loop iteration
8 mov x7, x2 // Store the initial value of x2, to be restored after the loop
9
10 // Load first column from the 16x6 matrix c
11 ld1 {v25.4s, v26.4s, v27.4s, v28.4s}, [x2], x5
12 // Load second column from the 16x6 matrix c
13 ld1 {v17.4s, v18.4s, v19.4s, v20.4s}, [x2], x5
14 // Load third column from the 16x6 matrix c
15 ld1 {v21.4s, v22.4s, v23.4s, v24.4s}, [x2], x5
16 // Load fourth column from the 16x6 matrix c
17 ld1 {v5.4s, v6.4s, v7.4s, v8.4s}, [x2], x5
18 // Load fifth column from the 16x6 matrix c
19 ld1 {v9.4s, v10.4s, v11.4s, v12.4s}, [x2], x5
20 // Load sixth column from the 16x6 matrix c
21 ld1 {v13.4s, v14.4s, v15.4s, v16.4s}, [x2], x5
22
23 mov x9, #64 // x9 iterator for K loop
24matmul_loop_over_K:
25 sub x9, x9, #1
26
27 // Load first column data from the 16x1 matrix a
28 ld1 {v0.4s, v1.4s, v2.4s, v3.4s}, [x0], x3
29
30 // run the known matmul_16_6_1_unrolled kernel
31 // Load first element from the 1x6 matrix b
32 ldr s4, [x1]
33 add x1, x1, x4
34
35 // Calculate first column of c
36 fmla v25.4s, v0.4s, v4.s[0]
37 fmla v26.4s, v1.4s, v4.s[0]
38 fmla v27.4s, v2.4s, v4.s[0]
39 fmla v28.4s, v3.4s, v4.s[0]
40
41
42 // Load second element from the 1x6 matrix b
43 ldr s4, [x1]
44 add x1, x1, x4
45
46 // Calculate second column of c
47 fmla v17.4s, v0.4s, v4.s[0]
48 fmla v18.4s, v1.4s, v4.s[0]
49 fmla v19.4s, v2.4s, v4.s[0]
50 fmla v20.4s, v3.4s, v4.s[0]
51
52
53 // Load third element from the 1x6 matrix b
54 ldr s4, [x1]
55 add x1, x1, x4
56
57 // Calculated third column of c
58 fmla v21.4s, v0.4s, v4.s[0]
59 fmla v22.4s, v1.4s, v4.s[0]
60 fmla v23.4s, v2.4s, v4.s[0]
61 fmla v24.4s, v3.4s, v4.s[0]
62
63
64 // Load fourth element from the 1x6 matrix b
65 ldr s4, [x1]
66 add x1, x1, x4
67
68 // Calculate fourth column of c
69 fmla v5.4s, v0.4s, v4.s[0]
70 fmla v6.4s, v1.4s, v4.s[0]
71 fmla v7.4s, v2.4s, v4.s[0]
72 fmla v8.4s, v3.4s, v4.s[0]
73
74
75 // Load fifth element from the 1x6 matrix b
76 ldr s4, [x1]
77 add x1, x1, x4
78
79 // Calculate fifth column of c
80 fmla v9.4s, v0.4s, v4.s[0]
81 fmla v10.4s, v1.4s, v4.s[0]
82 fmla v11.4s, v2.4s, v4.s[0]
83 fmla v12.4s, v3.4s, v4.s[0]
84
85
86 // Load sixth element from the 1x6 matrix b
87 ldr s4, [x1]
88 add x1, x1, x4
89
90 // Calculated sixth column of c
91 fmla v13.4s, v0.4s, v4.s[0]
92 fmla v14.4s, v1.4s, v4.s[0]
93 fmla v15.4s, v2.4s, v4.s[0]
94 fmla v16.4s, v3.4s, v4.s[0]
95
96
97 // offset x6 to the next element in the column
98 add x6, x6, #4 // #4 = sizeof(float)
99
100 // Restore x1 to be incremented again
101 mov x1, x6
102
103 // Loop back
104 cbnz x9, matmul_loop_over_K
105
106 // Restore initial value of x2 that was changed by the loads
107 mov x2, x7
108
109 // Store first column back to memory
110 st1 {v25.4s, v26.4s, v27.4s, v28.4s}, [x2], x5
111 // Store second column back to memory
112 st1 {v17.4s, v18.4s, v19.4s, v20.4s}, [x2], x5
113 // Store third column back to memory
114 st1 {v21.4s, v22.4s, v23.4s, v24.4s}, [x2], x5
115 // Store fourth column back to memory
116 st1 {v5.4s, v6.4s, v7.4s, v8.4s}, [x2], x5
117 // Store fifth column back to memory
118 st1 {v9.4s, v10.4s, v11.4s, v12.4s}, [x2], x5
119 // Store sixth column back to memory
120 st1 {v13.4s, v14.4s, v15.4s, v16.4s}, [x2], x5
2. Loop over M: Implement a kernel that computes C+=AB for M=64, N=6 and K=64.¶
File
submissions/submission_25_05_01/neon_3_2.s
1 // Offset the used leading dimension by the size of floats
2 lsl x3, x3, #2 // x3 * 4 = x3 * sizeof(float)
3 lsl x4, x4, #2 // x4 * 4 = x4 * sizeof(float)
4 lsl x5, x5, #2 // x5 * 4 = x5 * sizeof(float)
5
6 mov x6, x1 // Store the initial value of x1, to be restored in the K loop iteration
7 mov x7, x2 // Store the initial value of x2, to be restored in the K loop iteration
8
9 mov x8, x0 // Store the initial value of x0, to be restored in the M loop iteration
10 mov x9, x1 // Store the initial value of x1, to be restored in the M loop iteration
11
12 mov x16, #4 // x16 iterator for M loop
13matmul_loop_over_M:
14 sub x16, x16, #1
15
16 // ... <logic of loop over K - neon_3_1>
17
18 // next M iteration on the matrix c and matrix a, both need offset about 16 values
19 // also matrix b needs to start at the initial location again
20 // Updates for the matrix c
21 add x7, x7, #16*4 // column height * sizeof(float)
22 mov x2, x7 // also apply offset to x2
23
24 // Updates for the matrix a
25 add x8, x8, #16*4 // column height * sizeof(float)
26 mov x0, x8 // also apply offset to x0
27
28 // Updates for the matrix b
29 mov x6, x9 // Update the restore register for x1 for the K loop
30 mov x1, x9 // Update the x1 register itself
31
32 // Loop back to M
33 cbnz x16, matmul_loop_over_M
3. Loop over N: Implement a kernel that computes C+=AB for M=64, N=48 and K=64.¶
File
submissions/submission_25_05_01/neon_3_3.s
1 // Offset the used leading dimension by the size of floats
2 lsl x3, x3, #2 // x3 * 4 = x3 * sizeof(float)
3 lsl x4, x4, #2 // x4 * 4 = x4 * sizeof(float)
4 lsl x5, x5, #2 // x5 * 4 = x5 * sizeof(float)
5
6 mov x6, x1 // Store the initial value of x1, to be restored in the K loop iteration
7 mov x7, x2 // Store the initial value of x2, to be restored in the K loop iteration
8
9 mov x8, x0 // Store the initial value of x0, to be restored in the M loop iteration
10 mov x9, x1 // Store the initial value of x1, to be restored in the M loop iteration
11
12 mov x10, x0 // Store the initial value of x0, to be restored in the N loop iteration
13 mov x11, x2 // Store the initial value of x2, to bes restored in the N loop iteration
14 mov x12, #6 // hold the size of N that are processed in one loop, needed for offset calculation
15
16 mov x17, #8 // x17 iterator for N loop
17matmul_loop_over_N:
18 sub x17, x17, #1
19
20 // ... <logic of loop over M - neon_3_2>
21
22 // next M iteration on the matrix b and matrix c, both need offset about 6*ldb/ldc values
23 // also matrix a needs to start at the initial location again
24 // Update for the matrix a
25 mov x8, x10 // Update the restore register for x0 for the M loop
26 mov x0, x10 // Update the x0 register itself
27
28 // Updates for the matrix b
29 madd x9, x4, x12, x9 // ldb * 6 + initial position
30 mov x6, x9 // Update the restore register of x1 for the K loop
31 mov x1, x9 // Update the x1 register itself
32
33 // Updates for the matrix c
34 madd x11, x5, x12, x11 // ldc * 6 + initial position
35 mov x7, x11 // Update the restore register of x2 for the K loop
36 mov x2, x11 // Update the x2 register itself
37
38 // Loop back to N
39 cbnz x17, matmul_loop_over_N
1. Test and optimize the kernels. Report your performance in GFLOPS.¶
File
submissions/submission_25_05_01/neon_3.hTests
submissions/submission_25_05_01/neon_3.test.cppBenchmarks
submissions/submission_25_05_01/neon_3.bench.cpp
Optimization
Usage of already optimized matmul_16_6_1 from task 2.
Benchmarks
We run the benchmark with the following command:
./benchmarks --benchmark_counters_tabular=true --benchmark_repetitions=10 --benchmark_report_aggregates_only=true
----------------------------------------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations FLOPS
----------------------------------------------------------------------------------------------------------------------------------
GemmMxNxKFixture<16, 6, 64>/BM_matmul_16_6_64/min_warmup_time:1.000_mean 97.8 ns 97.4 ns 10 126.12G/s
GemmMxNxKFixture<16, 6, 64>/BM_matmul_16_6_64/min_warmup_time:1.000_median 97.7 ns 97.3 ns 10 126.245G/s
GemmMxNxKFixture<16, 6, 64>/BM_matmul_16_6_64/min_warmup_time:1.000_stddev 0.581 ns 0.563 ns 10 720.109M/s
GemmMxNxKFixture<16, 6, 64>/BM_matmul_16_6_64/min_warmup_time:1.000_cv 0.59 % 0.58 % 10 0.57%
GemmMxNxKFixture<64, 6, 64>/BM_matmul_64_6_64/min_warmup_time:1.000_mean 386 ns 385 ns 10 127.812G/s
GemmMxNxKFixture<64, 6, 64>/BM_matmul_64_6_64/min_warmup_time:1.000_median 385 ns 384 ns 10 127.95G/s
GemmMxNxKFixture<64, 6, 64>/BM_matmul_64_6_64/min_warmup_time:1.000_stddev 2.16 ns 2.11 ns 10 693.069M/s
GemmMxNxKFixture<64, 6, 64>/BM_matmul_64_6_64/min_warmup_time:1.000_cv 0.56 % 0.55 % 10 0.54%
GemmMxNxKFixture<64, 48, 64>/BM_matmul_64_48_64/min_warmup_time:1.000_mean 3103 ns 3092 ns 10 95.3736G/s
GemmMxNxKFixture<64, 48, 64>/BM_matmul_64_48_64/min_warmup_time:1.000_median 3097 ns 3087 ns 10 95.5363G/s
GemmMxNxKFixture<64, 48, 64>/BM_matmul_64_48_64/min_warmup_time:1.000_stddev 16.0 ns 15.6 ns 10 475.851M/s
GemmMxNxKFixture<64, 48, 64>/BM_matmul_64_48_64/min_warmup_time:1.000_cv 0.52 % 0.50 % 10 0.50%
Mean FLOPS for loop over K: 126.1 GFLOPS.
Mean FLOPS for loop over M: 127.8 GFLOPS.
Mean FLOPS for loop over N: 95.4 GFLOPS.